I agree that their wording is very misleading to many who read it. I would really love to see them make this more accurate. I ignore the summary statement that you point out. Then their write-ups are really useful. I think about how I evaluate variables. I brew something with my normal process. A few months later, I brew it with something changed - boil intensity, trub to fermenter, or whatever. I mentally compare the new beer with the one from a few months ago. Brulosophy's approach is about a million times better. Of course I still do my own taste test to "verify".I have no doubt they have discussed it. But, honest answer, if you would: If you knew nothing of statistics, and you read the words "... indicating participants in this xBmt were unable to reliably distinguish...", what would that mean to you?
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Value of brulosophy exbeeriments, others experience, myths and beliefs
- Thread starter mongoose33
- Start date

Help Support Homebrew Talk - Beer, Wine, Mead, & Cider Brewing Discussion Forum:
This site may earn a commission from merchant affiliate
links, including eBay, Amazon, and others.
You statisticians are taking this all way too seriously imo.
You statisticians are taking this all way too seriously imo.
If true, it's only because non-statisticians have blind faith in mischaracterizations from non-statisticians.
Nubiwan
Well-Known Member
- Joined
- Dec 1, 2018
- Messages
- 584
- Reaction score
- 364
At times, they might have 30 panelists and state they need some number, say its 19, to tell the difference, in order to show there is in fact a statistical difference. Not sure what term they use. I am also not sure how they arrive at that number "19". If close to half the people in their group (say 14 in my example) can detect a difference (or are they guessing - its not clear), then i find myself reading more on the findings. Not being fully convinced, despite what the tester states. Nearly half clearly could tell a difference, or guessed.
What is more telling to me, is when the number who can tell a difference is rather low. Or the brulosphy guys get stumped too. Also, when those who can tell the difference are then split over which one they preferred, then its rather getting down to personal preference, and taste. Depending on the variable, you might conclude, even if there is a difference in taste, who is to say it will be better tasting doing it one way or another.
What is more telling to me, is when the number who can tell a difference is rather low. Or the brulosphy guys get stumped too. Also, when those who can tell the difference are then split over which one they preferred, then its rather getting down to personal preference, and taste. Depending on the variable, you might conclude, even if there is a difference in taste, who is to say it will be better tasting doing it one way or another.
Last edited:
- Joined
- Jan 3, 2020
- Messages
- 2,297
- Reaction score
- 2,376
I will preface, I have been reading your posts but not critically as I felt the p-value was not particularly relevant as I stated. Regarding your p-value of 0.20. No, you wouldn't say that. If your p-value exceeds your significance level, you simply say no significant effect was observed. You don't couch your argument around the value of the p-value. I will try to properly explain. Suppose you pick alpha=0.05 as your significance level. That means 95 times out of 100 you will see data that you feel was generated under the conditions of the null hypothesis. Sometimes that data will be close to producing a test statistic close to the critical value, sometimes not. How close or not makes no difference because sometimes it will be close. That's why you pick your significance level a priori. Five times out of a hundred, it will be so different that you think to yourself, I don't believe that's the case that it came under the conditions of the null hypothesis. It's simply reported as significant. However, what you can do is put a confidence interval on say the significant difference between two treatments. Then you can say, well I found a difference of 0.01-0.05 units. Which could be so small as to be practically useless to you. And if it is a giganormous difference feel free to say soI never said or meant to imply that it was the rule, but rather used it as an exercise in logic. I could have picked 0.20 or 0.30, or really, anything less than 0.50. That's still a large amount of potentially misleading write-ups within the groups of experiments with those P-values. That said, I do think low-ish p-values have been more common in the experiments that include a real panel and not just one guy tasting the same beers over and over. If you look back through the archive, you'll find more than a few.
My point is that the standard blurb, when applied to them, is misleading to non-statisticians. Just looking at page two of the experiments, where they were all (I think) panel experiments, there were 37 experiments whose results earned them "the blurb." Of those, 14 (38%) had P-values of less than 0.30. So, for these 38%, the chances of getting at least the number of correct choices that were got due to random chance was, in every case, 29% or less. It's likely that a large portion of those panels detected a difference. But each and every one gets the standard blurb. That's my issue, and I think it's the only one I've raised in this thread. (Based on some responses, I think some folks might think I'm basically saying "Brulosphy sucks," but that's not what I'm saying at all.)
When the p-value is say, 0.20 (or whatever), would it not be helpful to say "Results indicate that if there were no detectable difference between the beers, there was a 20% chance of "X" <fill in the blank> or more tasters identifying the beer that was different, but "Y" tasters actually did."? IMO, that would give the readers something much more tangible on which to base their impressions, and their own risk of changing (or not) their own processes based on them.
ETA: and it might even reduce the number of *^$&*#&^ "Brulosophy debunked <X>" posts.
 . If the difference is not statistically significant, you wouldn't put a confidence interval on it because statistically the treatments are equal.
. If the difference is not statistically significant, you wouldn't put a confidence interval on it because statistically the treatments are equal. If you are really close, I wouldn't discard that line of thought. It's possible you didn't have enough power to determine a difference. You might have undersampled, maybe your samples have a lot of inherent variability.
I am also not sure how they arrive at that number "19". If close to half the people in their group (say 14 in my example) can detect a difference (or are they guessing - its not clear), then i find myself reading more on the findings. Not being fully convinced, despite what the tester states. Nearly half clearly could tell a difference, or guessed.
ASTM E1885. I have a copy but should not share based on copyright.
FWIW (nothing), I pay way more attention to any experiments where p<0.20, which is MY definition of where there MIGHT be a difference between two samples. This is based on detailed study of the ASTM and my own intuitive inputs.
With a lot of these to tests I assume even one layperson would be able to reliably identify the difference. That's how severe a lot of the dogma is in homebrewing.
I'm not gonna go through all the brulosophy tests, but the stuff I read about fermenting a lager at 60⁰ when i started brewing (around 8 years ago) made me 100% sure it would create a disgusting definitely off flavored beer.
Brulosophy showed that wasn't necessarily the case.
I ferment lagers at their recommended temps as I believe it creates a better beer, but the tests brulosophy and others do shows the "what if".
That's progress imo and learning.
Absolutely doesn't mean we should ferment lagers @70⁰ or only do 20 minute mashes, but I like knowing more.
I'm not gonna go through all the brulosophy tests, but the stuff I read about fermenting a lager at 60⁰ when i started brewing (around 8 years ago) made me 100% sure it would create a disgusting definitely off flavored beer.
Brulosophy showed that wasn't necessarily the case.
I ferment lagers at their recommended temps as I believe it creates a better beer, but the tests brulosophy and others do shows the "what if".
That's progress imo and learning.
Absolutely doesn't mean we should ferment lagers @70⁰ or only do 20 minute mashes, but I like knowing more.
VikeMan
It ain't all burritos and strippers, my friend.
- Joined
- Aug 24, 2010
- Messages
- 5,865
- Reaction score
- 5,988
I will preface, I have been reading your posts but not critically as I felt the p-value was not particularly relevant as I stated. Regarding your p-value of 0.20. No, you wouldn't say that. If your p-value exceeds your significance level, you simply say no significant effect was observed. You don't couch your argument around the value of the p-value. I will try to properly explain. Suppose you pick alpha=0.05 as your significance level. That means 95 times out of 100 you will see data that you feel was generated under the conditions of the null hypothesis. Sometimes that data will be close to producing a test statistic close to the critical value, sometimes not. How close or not makes no difference because sometimes it will be close. That's why you pick your significance level a priori. Five times out of a hundred, it will be so different that you think to yourself, I don't believe that's the case that it came under the conditions of the null hypothesis. It's simply reported as significant. However, what you can do is put a confidence interval on say the significant difference between two treatments. Then you can say, well I found a difference of 0.01-0.05 units. Which could be so small as to be practically useless to you. And if it is a giganormous difference feel free to say so
If you are really close, I wouldn't discard that line of thought. It's possible you didn't have enough power to determine a difference. You might have undersampled, maybe your samples have a lot of inherent variability.
I agree with this, from the perspective of having reached the (arbitrarily chosen) significance level or not. That's binary. But that does not mean that failing to reach that significance level means that there is no difference, which is what "the standard blurb" implies. I see nothing wrong with providing, in plain english, a percentage chance that the result was due to random chance. That's what the p-value does anyway, but the plain english would be more understandable. I do understand that it's not the kind of thing that would be written in an experimental research paper, where understanding of p-values is assumed. And I'm not advocating saying "Result was not significant, but boy it was close, so go ahead and pretend it did." I'm just advocating a plain english explanation of what the result means and doesn't mean for the lay person.
cgoldberg3
Well-Known Member
- Joined
- Mar 4, 2021
- Messages
- 73
- Reaction score
- 69
I decided to take their word on trub not having a negative affect on flavor when dumped into the fermenter - they were 100% right on that. I've used their ale fermentation schedule that involves ramping up to 75F at the end and that went perfectly well for me too.
- Joined
- Jan 3, 2020
- Messages
- 2,297
- Reaction score
- 2,376
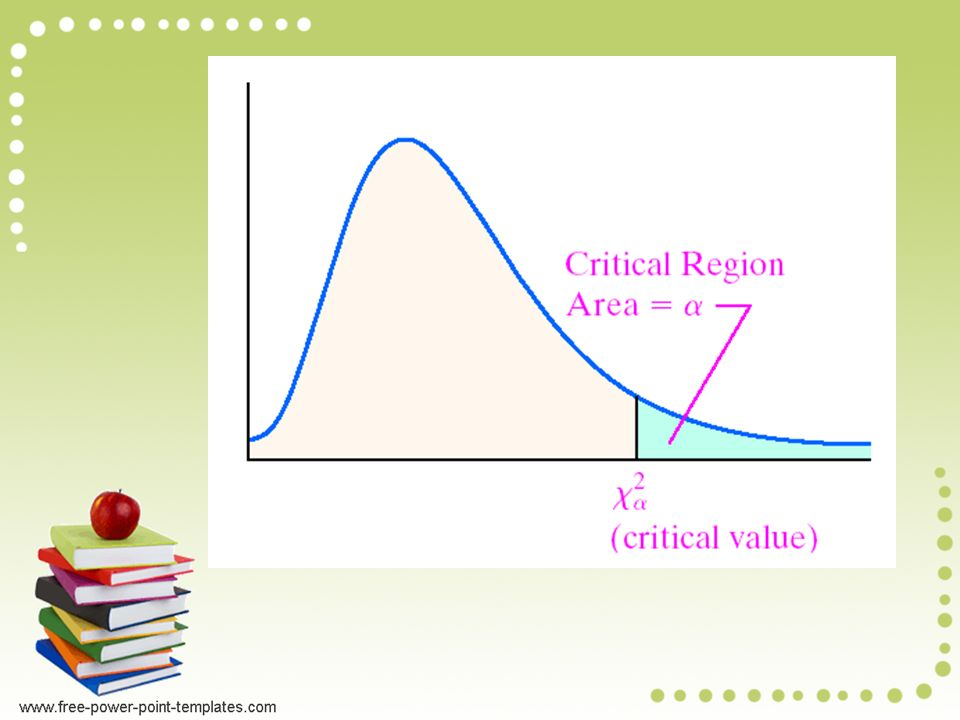
Darn it, it looks comprehensive to answer some of my own questions. I can mostly explain the critical value, how many they need correct. There's a probability distribution they compare the critical value to. The area under the curve sums to one (think 100%). A bell curve (normal curve) is one example. The one used here is called Chi-square. There's is a value on the curve for which the area to the end is equal to 0.05 (5%). If your test statistic exceeds this critical value, then you reject the null hypothesis.ASTM E1885. I have a copy but should not share based on copyright.

This link shows how to calculate the critical value. If you look at the summation under Data Analysis, you can iterate the value for O (the observed), until you find the number of observed that puts you greater than the critical value from the Chi-square curve. E(The expected) is fixed at 1/3 total of testers for correct responses and 2/3 the total of testers for incorrect responses. You have to do that [(O-E)^2]/E once for the correct responses and once for the incorrect.
The specific Chi-square curve used has one degree of freedom. Data for Chi-square analysis is typically laid out in tables and I believe the degrees of freedom is the number of cells minus 1. These days, you feed the data in and the computer would do the rest. Probably spits out the critical number of responses needed to be significant if its in a stats package.
Attachments
- Joined
- Jan 3, 2020
- Messages
- 2,297
- Reaction score
- 2,376
I agree with this, from the perspective of having reached the (arbitrarily chosen) significance level or not. That's binary. But that does not mean that failing to reach that significance level means that there is no difference, which is what "the standard blurb" implies. I see nothing wrong with providing, in plain english, a percentage chance that the result was due to random chance. That's what the p-value does anyway, but the plain english would be more understandable. I do understand that it's not the kind of thing that would be written in an experimental research paper, where understanding of p-values is assumed. And I'm not advocating saying "Result was not significant, but boy it was close, so go ahead and pretend it did." I'm just advocating a plain english explanation of what the result means and doesn't mean for the lay person.
My opinion is you should not do that because you are still only telling part of the story. "With 95% confidence, we did not see a difference between the two treatments." If I repeated the experiment 100 times, 95 times I would find no difference. Provided my statistical methodology is correct, I am not violating assumptions, etc. You aren't acknowledging the confidence level in your second quote. Statistically, you should know you will see close values sometimes but you have to have personal confidence in your confidence level. Otherwise you are not confident. So pick it but do it beforehand, a priori, so you are not tempted to do these things. If it is close, trust the test, but maybe in the future verify with a new experiment. But don't undermine your own statistical test otherwise why use it if you don't trust it?They are absolutely not completely neutral with regards to the interpretation of results. In experiments where they find a P-value of, say, 0.06, they use these standard words: "... indicating participants in this xBmt were unable to reliably distinguish..."
A p-value of 0.06 means that if there were actually no detectable difference, there was only a 6% chance that as many (or more) tasters would have chosen the odd beer as actually did. Does that sound to you like there's very likely not a difference?
They absolutely could be completely neutral if they instead said "Results indicate that if there were no detectable difference between the beers, there was a 6% chance of "X" <fill in the blank> or more tasters identifying the beer that was different." That would be neutral and accurate.
Now one thing that does make me not trust a statistical test is an inadequate sample size.
BrewnWKopperKat
ʘ‿ʘ
In the end, most of us will only get to taste OUR beer results ourselves, and perhaps share with a few friends or family.
Yup. Perhaps that is why it is called home brewing.

Now one thing that does make me not trust a statistical test is an inadequate sample size.
Great point. By my review of the ASTM standard, I figure they should be aiming for at least 40 if not 45+ tasters per experiment for somewhat valid results. Otherwise... meh...
madscientist451
Well-Known Member
I'd rather listen to a Brulosphy podcast than watch a baseball all-star game or view another coke commercial, its just way more entertaining.....
It’s flawed. Sure they’d like to get 40 tasters but most of us get about 3 and make no effort to blind them to the style, variable, or expected outcome. But still if you put up a post about your experience brewing and tasting a split batch with your homebrew buddies I’d read it and be interested. If I decided meh I’d probably keep that to myself though.Great point. By my review of the ASTM standard, I figure they should be aiming for at least 40 if not 45+ tasters per experiment for somewhat valid results. Otherwise... meh...
They make an effort to get rid of confirmation bias in their tests. Thats pretty much the story. Confirmation bias seems to be a powerful bias and when they control its ability to sway results interesting data points that lead to questioning modern understanding of historical practices sometimes emerge. It’s interesting or we’d not still be debating it.
Nubiwan
Well-Known Member
- Joined
- Dec 1, 2018
- Messages
- 584
- Reaction score
- 364
This!It’s flawed. Sure they’d like to get 40 tasters but most of us get about 3 and make no effort to blind them to the style, variable, or expected outcome. But still if you put up a post about your experience brewing and tasting a split batch with your homebrew buddies I’d read it and be interested. If I decided meh I’d probably keep that to myself though.
They make an effort to get rid of confirmation bias in their tests. Thats pretty much the story. Confirmation bias seems to be a powerful bias and when they control its ability to sway results interesting data points that lead to questioning modern understanding of historical practices sometimes emerge. It’s interesting or we’d not still be debating it.
Someone might do a split batch to perhaps try different yeasts on a recipe, different dry hops, different ferment temps, and post findings in HBT. Or even refer to one they did in the past. Doesnt happen an awful lot, from what i have seen, but ive seen people refer to it. In general, posts that do so are appreciated, interesting to note, and filed for later personal referral.
Brulosophy do this all the time, with considerable attention to process, never mind trying to find testers, and the "adults" on HBT just want to ridicule it as (p-value) nonsense. The reality is, its nothing more than another piece of the brewing puzzle Brulosphy are offering. At the very least, interesting and provocative. What harm does it do to think outside the box a little?
Is it just a case of equipment envy?
Hey! Teacher! Leave them kids alone.
- Joined
- Jan 3, 2020
- Messages
- 2,297
- Reaction score
- 2,376
I have absolutely no idea what any of their equipment looks like. It's been about a while since I have even read any of their writeups. Judging from the manner in which some people speak of them, I'm sure the Brulosophy guys have their good points too. However, when all they are analyzing is a split batch, that's just a sample size of one and to me it doesn't have much more weight than if any other HBT member did the same experiment. If what they are doing is really thought provoking and outside the box comparisons, that's when you really want to have the weight of the evidence behind you. You can't do that when you have only one sample, no matter how sophisticated you portray the data, or rather datum.
But no, I'm not envious of their equipment. I have seen some nice brew rigs and brew caves here on HBT. I am pretty happy and grateful for my own setup, which I mainly built myself.
 and here's my jockey box along with 10 and 15 gallon kegs,
and here's my jockey box along with 10 and 15 gallon kegs,

and my ferm chambers,
 .
.
Now I will hold off on showing my keezer which is almost done but the chairs I'm building aren't there yet. Sure I'd love to have a conical but then I'd want to build a glycol chiller and one of my children would be upset this summer.
But no, I'm not envious of their equipment. I have seen some nice brew rigs and brew caves here on HBT. I am pretty happy and grateful for my own setup, which I mainly built myself.
and my ferm chambers,
Now I will hold off on showing my keezer which is almost done but the chairs I'm building aren't there yet. Sure I'd love to have a conical but then I'd want to build a glycol chiller and one of my children would be upset this summer.
VikeMan
It ain't all burritos and strippers, my friend.
- Joined
- Aug 24, 2010
- Messages
- 5,865
- Reaction score
- 5,988
Brulosophy do this all the time, with considerable attention to process, never mind trying to find testers, and the "adults" on HBT just want to ridicule it as (p-value) nonsense.
Strawman argument. Nobody has said Brulosophy is nonsense, or at least I haven't. But we have levelled fair, reasoned criticisms about important, but fixable, aspects. My issue in particular would be a breeze to fix.
Is it just a case of equipment envy?
Ad hominem argument. It happens to be wrong, but it's irrelevant anyway. It would really be more productive if we could stick to debating facts.
Last edited:
Nubiwan
Well-Known Member
- Joined
- Dec 1, 2018
- Messages
- 584
- Reaction score
- 364
Provacative enough for you to whip out your package and show off.I have absolutely no idea what any of their equipment looks like. It's been about a while since I have even read any of their writeups. Judging from the manner in which some people speak of them, I'm sure the Brulosophy guys have their good points too. However, when all they are analyzing is a split batch, that's just a sample size of one and to me it doesn't have much more weight than if any other HBT member did the same experiment. If what they are doing is really thought provoking and outside the box comparisons, that's when you really want to have the weight of the evidence behind you. You can't do that when you have only one sample, no matter how sophisticated you portray the data, or rather datum.
But no, I'm not envious of their equipment. I have seen some nice brew rigs and brew caves here on HBT. I am pretty happy and grateful for my own setup, which I mainly built myself. View attachment 725004and here's my jockey box along with 10 and 15 gallon kegs,
View attachment 725005
and my ferm chambers,
View attachment 725006.
Now I will hold off on showing my keezer which is almost done but the chairs I'm building aren't there yet. Sure I'd love to have a conical but then I'd want to build a glycol chiller and one of my children would be upset this summer.
Now, indeed, i have equipment envy. Where is my bag? Seems so tiny.
")
Last edited:
Provacative enough for you to whip out your package and show off.
Now, indeed, i have equipment envy. Where is my bag? Seems so tiny.
Very few people would envy my equipment. I've got a nice bag
, but beyond that...I have brewed about 160 batches on my stove top in a 4-gallon kettle and various kitchen pots. I still bottle most batches but recently got a uKeg Go 128-oz. That's as high tech as I get here. And -- I do not mean to show off but just stating a fact -- still manage to have a drawer full of ribbons and medals. YMMV.
Cheers all.
I doubt if even kittens can save this thread but, just in case, here’s a picture of the 4 day old kittens one of our barn cats had on the backseat of an old car body behind the machine shed.

This is a forum for hobbyist homebrewers. The Brulosophy guys found a way to monetize a hobby. BF deal. You may now return to your regularly scheduled argument over how many homebrewing angels should be allowed to dance on the head of the scientific pin.
This is a forum for hobbyist homebrewers. The Brulosophy guys found a way to monetize a hobby. BF deal. You may now return to your regularly scheduled argument over how many homebrewing angels should be allowed to dance on the head of the scientific pin.
Chuckbergman
Well-Known Member
IIRC, in those threads, there are a couple of people who offered "no boil, DME (or LME), pasteurized" recipes for styles other than NEIPA.
I did a no boil NEIPA last year. Just a 3 gal. batch to test the process. The beer was good, definitely not great and definitely not as good a my traditional boil NEIPA recipe. Using only DME you get a very light body. The hop flavors and juiciness did come thru.
I did a no boil NEIPA last year. Just a 3 gal. batch to test the process. The beer was good, definitely not great and definitely not as good a my traditional boil NEIPA recipe. Using only DME you get a very light body. The hop flavors and juiciness did come thru.
You got a p value on that comparison? @Chuckbergman claims to have proven no boil NEIPA sucks folks. Move along nothing to see here.
oh @Chuckbergman just noticed you are pretty new here. Green font is sarcasm. Didn't mean to pick on you thanks for sharing the experience!
You may now return to your regularly scheduled argument over how many homebrewing angels should be allowed to dance on the head of the scientific pin.
Or, camels dancing in the eye of a needle?!
- Joined
- Apr 3, 2018
- Messages
- 340
- Reaction score
- 365
This is a forum for hobbyist homebrewers. The Brulosophy guys found a way to monetize a hobby. BF deal. You may now return to your regularly scheduled argument over how many homebrewing angels should be allowed to dance on the head of the scientific pin.
I think homebrewers can become so passionate (obsessive?) about this hobby that sometimes we tend to go beyond what most ordinary people would consider a sane discourse. I said we because I obviously put myself into this category as well. Hell I still regret my involvement in an absolutely pointless argument with the **************** folks about one year ago.
beersk
Well-Known Member
- Joined
- Mar 22, 2013
- Messages
- 1,855
- Reaction score
- 1,032
I can guess who you're referring to as there aren't really any other people that anyone starts huge arguments with on the homebrewing forums since, oh, about March of 2016. Although, admittedly I am one of those people since those early days, but not one to argue about it. But I'd put myself into this obsessive category as well and it seems to have gotten worse with the pandemic/wfh life. I'm trying to work on that.I think homebrewers can become so passionate (obsessive?) about this hobby that sometimes we tend to go beyond what most ordinary people would consider a sane discourse. I said we because I obviously put myself into this category as well. Hell I still regret my involvement in an absolutely pointless argument with the **************** folks about one year ago.
- Joined
- Apr 3, 2018
- Messages
- 340
- Reaction score
- 365
it seems to have gotten worse with the pandemic/wfh life. I'm trying to work on that.
Same here
BrewnWKopperKat
ʘ‿ʘ
The "no boil, DME, pasturized" technique works for some, doesn't work for others.I did a no boil NEIPA last year. Just a 3 gal. batch to test the process. The beer was good, definitely not great and definitely not as good a my traditional boil NEIPA recipe. Using only DME you get a very light body. The hop flavors and juiciness did come thru.
I posted the links to help others find the the topics that were mentioned.
- Joined
- Jan 3, 2020
- Messages
- 2,297
- Reaction score
- 2,376
One of the first things a homebrewer friend said to me after I completed my brewing rig was "Now you can Brulosophy that s&$t!" Although perhaps not evident, my friend is a scientist and was referring to paired sampling, which is extremely helpful in cutting out the noise (up to the split) from variations in brewing different batches. It's a good tool to add your toolbox and if people are picking that up from Brulosophy that's a plus all around.
Nubiwan
Well-Known Member
- Joined
- Dec 1, 2018
- Messages
- 584
- Reaction score
- 364
I need to change my default text colour to green FFS. A lot of "seriosity" on this thread.oh @Chuckbergman just noticed you are pretty new here. Green font is sarcasm. Didn't mean to pick on you thanks for sharing the experience!
Nubiwan
Well-Known Member
- Joined
- Dec 1, 2018
- Messages
- 584
- Reaction score
- 364
Well, shame on you Dave. My first greenie - eughh!Very few people would envy my equipment. I've got a nice bag
I have brewed about 160 batches on my stove top in a 4-gallon kettle and various kitchen pots. I still bottle most batches but recently got a uKeg Go 128-oz. That's as high tech as I get here. And -- I do not mean to show off but just stating a fact -- still manage to have a drawer full of ribbons and medals. YMMV.
Cheers all.
Nubiwan
Well-Known Member
- Joined
- Dec 1, 2018
- Messages
- 584
- Reaction score
- 364
Not sure they are alone monetizing their website. Seems homebrewtalk is interested in where I go too. What's good for the goose.I doubt if even kittens can save this thread but, just in case, here’s a picture of the 4 day old kittens one of our barn cats had on the backseat of an old car body behind the machine shed.View attachment 725011
This is a forum for hobbyist homebrewers. The Brulosophy guys found a way to monetize a hobby. BF deal. You may now return to your regularly scheduled argument over how many homebrewing angels should be allowed to dance on the head of the scientific pin.

2011 is recent. Dang, i'm a total noob. LOLoh @Chuckbergman just noticed you are pretty new here. Green font is sarcasm. Didn't mean to pick on you thanks for sharing the experience!
That was my first too. I learn so much from this site. LOLWell, shame on you Dave. My first greenie - eughh!
hmm right you are I was looking at 36 posts since joining thats a lot of lurking
I didn't even know that was there. Learn something new all the time.hmm right you are I was looking at 36 posts since joining thats a lot of lurking
I'm here for the "seriosity"!I need to change my default text colour to green FFS. A lot of "seriosity" on this thread.
Nubiwan
Well-Known Member
- Joined
- Dec 1, 2018
- Messages
- 584
- Reaction score
- 364
I like sites that do testing of different methods. Exercise the thought process, rather than try define it.
These fellas don't seem to get many mentions on HBT. Some more interesting stuff that they have their own members try and compare, and report finings. I read a couple of them. Interesting! So a shout out to them is all this is.
https://www.experimentalbrew.com/
These fellas don't seem to get many mentions on HBT. Some more interesting stuff that they have their own members try and compare, and report finings. I read a couple of them. Interesting! So a shout out to them is all this is.
https://www.experimentalbrew.com/
Similar threads
- Replies
- 8
- Views
- 3K
- Replies
- 17
- Views
- 2K
- Replies
- 3
- Views
- 1K
